我々は、データサイエンスの価値を引き出し、社会を変えていくために存在する組織です。国内上場企業・業界大手企業、医療機関、医療学会、多国籍企業や、資金調達後のスタートアップ(一部)を対象に、データサイエンス・人工知能領域のR&D、データサイエンスを活用した事業改善や新規事業推進、人材開発など、あらゆる側面から支援を行います。
設立の背景と目的 / データサイエンスを担う人材の不足
「Fortune 500社の内の85%は、2015年までにビッグデータを競合優位性に結びつく水準にまで活用することに失敗する。」
“Through 2015, 85% of Fortune 500 organizations will be unable to exploit big data for competitive advantage.”
ガートナー社により2012年の展望として出されたこの見解は、ビッグデータに関心を持つ多くの企業経営者・担当者に共感を持って受け止められました。*1
現在、企業が手にすることのできるデータ量は指数関数的に大きくなっています。
センサーとカメラを搭載したスマートデバイスの普及、ハードウェアの低廉化と大規模データを捌く技術の高度化・オープンソース化により、「文明の始まりから21世紀初頭までに生産された情報量(約5エクサ・バイト)に匹敵する情報量が、現代社会ではたった2日で生産される(グーグル会長エリック・シュミット)」と言われる程です。
データが増えるということは、当然、そのデータを扱うスキルを持つデータサイエンティストも必要になります。
しかし、そうしたデータサイエンティストの人数は需要に対して全く足りていません。
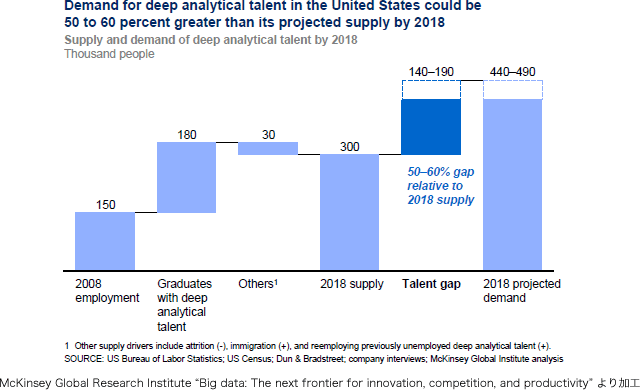
McKinsey Global Instituteによれば、米国だけで2018年までに必要とされるデータサイエンティスト数が約44~49万人となるのに対し、14-19万人不足し、データサイエンスの知識を持つ企業役員や補助スタッフに至っては150万人必要になると予測されています。*2
日本においても、データサイエンティストと呼ばれる専門人材育成を目的とした、人材要件の定義、講座・セミナーの開設を行なう団体が増え、書籍・雑誌の特集も増えてきています。
このように専門人材育成の機運が盛り上がる一方で、ビッグデータ活用を単にツール・インフラ導入で終わらず、真に価値あるインパクトへ繋げるための道筋は未だに不透明であるというのが各企業経営者・担当者にとっての偽らざる実感ではないでしょうか。
学術分野としてのデータサイエンスは、既存の学問領域の枠を超えており、統計学や数学、コンピューターサイエンスや並列分散処理プログラミングに加えた学際的なものとして進化し、また、分析対象となる専門分野の知識も求められるため、一人の人間がそれら全てに通暁する事は難しくなってきています。
さらに、データ活用はデータを解析すれば終わりではありません。データサイエンスが社会的・経済的インパクトを実現するためには、ビッグデータ活用を継続的な競争優位性に繋げる事業構想力、利害関係の異なる組織を動かす調整力、日々の事業データから最適化を促進する力も必要とされます。
データサイエンティストの人材像
私たち日本データサイエンス研究所では、これまで理想として語られてきたデータサイエンティストと、現実に調達可能なリソースの間に、大きなギャップが存在していると考えています。
従来は、テクノロジー × サイエンス × ビジネスを高次元で統合したスーパータレントとしてのデータサイエンティスト像が語られてきました。大きなビジネスインパクトの源泉を特定し、その実現のための科学的な検証方法を構築し、アルゴリズムを書き出し、通信環境や分散処理のハードウェア知識も活かして企業の問題を解決するスーパーマンのようなイメージが、データサイエンティストという訳です。
しかし、現実にはこのような人材を一般的な企業で育成・採用できる可能性は限りなく低く、事業としての実現スピード・再現性・スケールを期待することもできません。
とりわけ、トップクラスのタレントについては、Google, Apple, Facebook, Amazonなどデータ・インフラ・資金力・圧倒的な研究環境(専門人材ネットワーク)を持つデータサイエンスのエクセレントカンパニーでも獲得に苦労しており、政府機関や学術機関との人材争奪戦にもなるため、ごく一般的な企業にとってはこうしたスーパータレントの採用難易度は非常に高いと言わざるをえないでしょう。
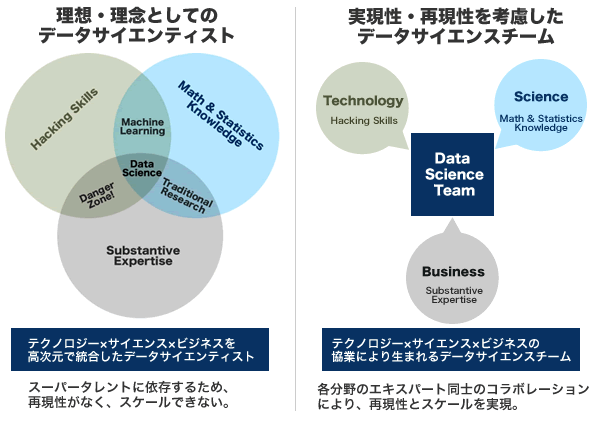
一人の大天才に依存する理想像に対して、テクノロジー × サイエンス × ビジネス、各分野のエキスパート同士のコラボレーションによる「データサイエンスチーム」のアプローチが、より多くの企業のビッグデータ活用にとって、実現スピード・再現性・スケールの面で、より可能性があると当研究所は考えています。
データサイエンティスト依存からデータサイエンスチーム協働への進歩するためには、各分野のエキスパート同士のコラボレーションを円滑にするための仕組みが必要なのです。
仕組みは、単にそれぞれの担当者を採用し、週次のミーティングを設定するだけで作られるものではありません。
仕組みが継続的に機能するためには、チームが共通の目標に向かって協力するための仕掛け、お互いが共通言語でコミュニケーションできる事、それぞれに求められる役割が明確で、それに見合ったスキルを備えた人材が採用され、トレーニングされ、評価される仕掛け、互いに改善のためのフィードバックが機能するメカニズムなど、多くの小さい仕掛けが有機的に連携して初めて、各分野のエキスパートが有効にコラボレーションできるようになります。
これは簡単なことではありませんが、1つずつステップを踏めば、一般企業であっても十分達成可能なものであると私達は考えます。
日本データサイエンス研究所では、こうした見立てのもと、テクノロジー、サイエンス、ビジネスのコミュニケーションギャップを埋め、コラボレーションを促進するためのデータサイエンス研究を各分野の有志とともに行なっていきます。
- *1 Gartner Predict http://www.gartner.com/technology/topics/big-data.jsp
- *2 McKinsey Global Research Institute “Big data: The next frontier for innovation, competition, and productivity”
http://www.mckinsey.com/insights/business_technology/big_data_the_next_frontier_for_innovation
具体的な活動
上記のミッションを達成するために行う、日本データサイエンス研究所の活動
データ活用についての事業コンサルティング
- データを活用したビジネスプロセスの改良
- データ、人工知能の活用テーマ探索・デジタルプロトタイピングと実装
- 新規事業の立案から実行・運用までの帆走と、事業立ち上げについての能力移転
ITシステムの開発・運用
- ITシステムの刷新に伴うシステム構築
- アルゴリズム、特に機械学習を用いたものの開発とライセンス・API提供
- データメンテナンス、システムの保守・運用
事業投資
- データによる価値創造を梃子にした事業投資
- 投資先企業に対するハンズオン支援
- データサイエンスの応用領域、応用価値拡大のための理論研究活動・理論の体系化
- 理論:成功事例を支える機械学習や統計モデルおよび大規模並列分散処理の理論的な側面の解説(何ができ、何ができないか、手法別のメリット・デメリットなど)
- 事例:ビッグデータ活用の成功事例・失敗事例のケーススタディ
- 実践:データの蓄積、フィルタリング、解析、実行からビジネスインパクトにつなげるためのテクニカルな手続き的知識の補強
- 書籍、ホワイトペーパー、などを通じた、データサイエンスリテラシーの向上
- 研修を通じた、データサイエンスを担う人材開発
- ビジネス基礎・問題解決能力の開発を目的とした研修
- 新規事業立ち上げについての研修
- データサイエンスチームを構成する各エキスパートの足りない能力を補完する研修
- 専門分野特化型の研修
- データサイエンティストの定義・スキル認証、活動領域の明確化
- データサイエンス活用に課題を有する団体 (アカデミア、企業、政府機関、医療施設や一般団体) と、データサイエンティストとして活躍したいと考える人材のマッチング支援
- 団体の紹介とミッション
- データサイエンスの価値
- データサイエンティストの役割 6類型と4類型のハイブリッド
- 団体概要