Analytics 3.0の時代
0企業活動における分析の位置づけはどう変化してきたのか
Artwork: Chad Hagen, Nonsensical Infographic No. 5, 2009, digital
Harvard Business Reviewの 2013 Decemberの特集に、Thomas Davenport氏によるAnalytics 3.0が投稿されました。彼は、Thomas Davenport氏は「データサイエンティストほど素敵な職業はない」 http://hbr.org/2012/10/data-scientist-the-sexiest-job-of-the-21st-century/ の寄稿でも有名な、ボストン・カレッジの教授ですが、なかなか興味深いレビューでした。
本投稿では彼の投稿に倣って、分析の位置づけがどう変わってきたのか、振り返ります。
Analytics 1.0 – 単なるビジネスインテリジェンス
初めてコンピューターが登場した頃から、2000年前位までの時代を筆者はざっくりと「同じ時代」にまとめています。「過去どういう事が起こったか」の情報を提供するだけの役割を分析活動が担っていた時代としています。
分析手法で言えば、単なる記述統計でイベントを時系列で示したり、平均や分散・四則演算程度の初歩的な手法が、数的処理活動の殆どを占めます。
コンピューターがごく一部の大企業に入り始めた黎明期と、大企業のほとんどが日常的にコンピューター2000年を同カテゴリに分類することには多少の違和感を感じるかもしれませんが、何も特定の時代において1種類の分析メソッドしか使われないと言っているわけではありません。実際、現在でも四則演算が不要になってもいません。ここでの分類は、企業に対する「分析活動」の付加価値やその数的処理の手法でいえば、1950年も2000年も実は大した違いはないですよね、という訳です。ERPツール (Enterprise Resource Planning) は今でも役割を失っているわけではありませんし、むしろ入手できるデータが増えることで、こうしたツールへのニーズが高まっているように見えます。

business intelligence tool (ex SAP)
Analytics 2.0 – ビッグデータのWeb活用
さて、分析の果たす役割に、質的な違いを持つものが登場するには、21世紀まで待たなければなりません。GoogleやeBayといったシリコンバレーの企業が興隆し、大規模なデータベースを使った分析を行う時代です。
Analytics 1.0時代の単なるビジネスインテリジェンスの役割を超え、Amazonが「この商品を買ったひとは、こんな商品も買っています」というオススメに使ったり、LinkedInやTwitterが「この人・会社もフォローしては?」というオススメをしてくるなど、今までにはなかった設計思想・数的処理・それを支えるデータベースインフラが運用されます。しかし、まだまだ一般企業が広くビッグデータの恩恵を受ける訳ではなく、Webベースのサービスを提供している企業が2.0の主要プレイヤーです。
分析手法でいえば、レコメンデーションやパーソナライゼーションに必要なのは相関解析・多変量解析ですが、とはいえAnalytics 1.0時代の四則演算が無くなるわけでは全くなく、むしろボリュームで言えば1.0時代のもののほうが多いはずです。
少し専門的になりますが、データベースの技術論で言えば、昔はRDBMS (Relational DataBase Management System)という、縦と横でなんのデータがどうやって入っているかはっきりと定義されたものがあれば大抵の課題を処理することが出来ましたが、データベースの特性上、ほんの一部分を取り出して計算することができないため、データ量が大きくなればなるほど処理スピードが実ビジネスの要求に合わないほど遅くなってしまうようになりました。インデックスという、辞書の索引のような仕組みを毎回付け直すにしても、やはりデータが大きくなると加速度的に処理が重くなる傾向にありました。
そのため、NoSQLという新しい仕組みのデータベースシステムを導入する事で、計算負荷を制限しながらデータの一部だけを取り出す事を可能にすることで、ビジネス要求に合わせた分析を行うようになりました。

nosql database management system
Analytics 3.0 – Webからリアルでのビッグデータ活用へ
ボッシュグループ(約130年の歴史を持つドイツの電動工具メーカー)が、電気自動車の充電最適化やエネルギー最適化など、既存事業の生産性向上にデータを活用していることや、シュナイダーエレクトリック(設立後約170年の老舗電気機器メーカー)が、スマートグリッドを含むエネルギーマネジメントでビッグデータを活用している事が例として引用されていますが、ビッグデータがWeb外で、情報以外の財・サービスに付加価値を与えるフェーズがAnalytics 3.0です。
日本国内の例でも、いわゆるオールドエコノミーの代表である農業において、例えばカルビーはセンサーでじゃがいも農場のデータを分析し、生産性の向上に活用している事が知られています。大量の気象センサーで既往・音頭・降水量・日射量といったデータを10分ごとに取得し、個別農家1人1人の直感的な判断では追いつかないような判断をリアルタイムで実施しているそうです。
2週間後、疫病発生が見込まれます。すみやかに疫病の予防作業に着手して下さい。今年6月、カルビーポテトは、約1100の契約農家の携帯電話やスマートフォンに、このような内容のメッセージを一斉配信した。 – 2013年12月 日経情報ストラテジー
重機メーカーのコマツも、KOMTRAXと呼ばれる機械かどう管理システムを2001年から提供しています。各重機にGPS・通信システムが搭載されており、車両センサーからの情報を、衛星を通じて顧客やコマツへと情報のフィードバックを行っているとされています。
この神経系が機能することで、故障の予知や車両稼働状況の可視化・位置把握が実現されています。重機の使用マーケットは圧倒的に発展途上国が多いため、盗難や債権回収など従来は解消が難しいとされてきた課題についても、データによる解決が可能になっています。
![komtrax_image01[1]](http://bigdata.sakura.ne.jp/db/wp-content/uploads/2014/01/komtrax_image011.jpg)
全ての企業にとって、”Compete on Analytics”が勝敗を決する時代へ
この様に、ビッグデータの活用や、その分析の巧拙によって当該企業の競争優位性が大きく影響される事は、どの産業にとっても既に他人ごとではなくなってきています。ビッグデータはウェブ企業だけのものだと考えていたとすれば、自分の時代認識がAnalytics 2.0で止まってしまっていると理解を改める必要があるように思います。
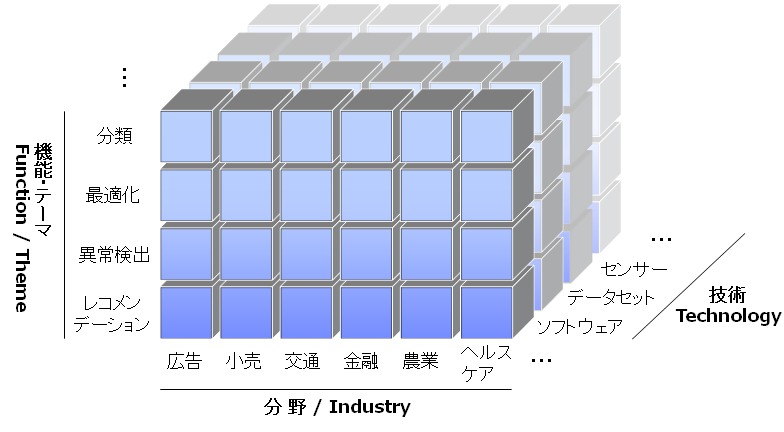
今やデータサイエンスの活用領域の広がりはもっと多様であり、そのテーマも多岐にわたるものとなっています。下図はその広がりを模式的に機能・テーマ、産業分野、それらを実現する要素技術のグリッドを表現したものです。
機能・テーマには、レコメンデーションや異常検出、パーソナライゼーションも含めた最適化、分類といったものがありますが、これだけではなく日進月歩で拡大を続けています。活用される産業についても同様です。HBRで挙げられている上記の例は電気機器ですし、カルビーは農業において、コマツは重機というマーケットでの活用例でした。
自社の次なるデータ・ドリブン・イノベーションのフロンティアを検討する際には、こうして縦軸・横軸・奥行きを可視化すると、ある程度短時間で網羅的な検討が系統的に行い易く、効果的です。